Testfragen
Welche Bedingung (bzg. der Stack-Höhe) erfüllt der Code für eine (virtuelle) Stack-Maschine, der bei Kompilation a) eines Ausdrucks, b) einer Anweisung entsteht?
Wozu sind bei der Implementierung von Unterprogramm-Aufrufen im Allgemeinen sowohl dynamische als auch statische Kette nötig? Wieso benötigt man für C-Programme keine statische Kette?
Für welchen Verwendung von Unterprogrammen ist es nicht ausreichend, die dynamische Kette durch zusätzliche Verweise zwischen Stack-Frames zu implementieren?
Gegeben sind Wörter
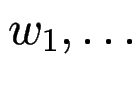 und reguläre Ausdrücke
und reguläre Ausdrücke
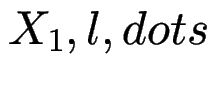 .
Finden Sie alle Paare
.
Finden Sie alle Paare 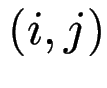 , für die
, für die
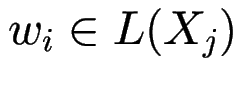 .
.
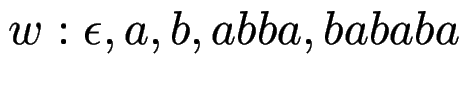
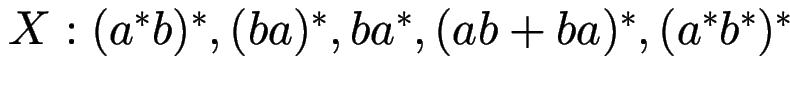
Warum sind nicht-deterministische Automaten während der Herstellung eines (flex-)Scanners natürlich und nötig, aber beim tatsächliche Einsatz des Scanners unerwünscht?
Auf welche (zwei) Arten überträgt ein flex-Scanner zur Laufzeit Informationen an einen bison-Parser?
Welche Information benötigt der Scanner vom Parser zur Compile-Zeit?
Erklären Sie am Beispiel eines Integer-Tokens.
Welche Tokenklassen gibt es in den üblichen Programmiersprachen?
Wie implementieren Sie in einem flex-Scanner
das Ignorieren von Kommentaren
zwischen // und Zeilenende?
Geben Sie für die Grammatik
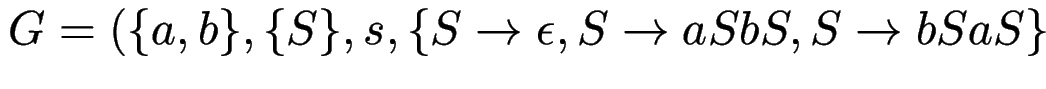 zwei verschiedene Links-Ableitungen (mit dazugehörigen Ableitungsbäumen)
für das Wort
zwei verschiedene Links-Ableitungen (mit dazugehörigen Ableitungsbäumen)
für das Wort ![]() .
.
Worin besteht das Problem des ,,hängenden else``(dangling else)? Geben Sie ein Beispiel.
Nennen Sie die Arbeitsschritte (shift/reduce)
und den jeweiligen Stack-Inhalt
eines Operator-Präzedenz-Parsers
für die Eingabe
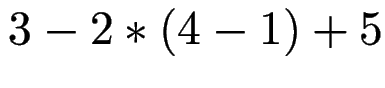 bei den üblichen Vorrang-Regeln.
bei den üblichen Vorrang-Regeln.
Wieso sind deterministische Bottom-Up-Parser weiter (d. h. für mehr Sprachen) einsetzbar als deterministische Top-Down-Parser?
Wieso können Top-Down-Parser verständlichere Fehlermeldungen liefern als Bottom-Up-Parser?
Welche Typen müssen die Funktionen ![]() haben,
damit das folgende korrekt ist:
haben,
damit das folgende korrekt ist:
length ( f ( map g [ 1 .. 10 ] ) ) wobei map :: (a -> b) -> ([a] -> [b])
Welche Möglichkeiten der Optimierung sehen Sie (ggf. unter welchen zusätzlichen Voraussetzungen)?
int f (int n, int a) {
int s = 0;
for (int i=0; i<n; i++) {
s += g(a) * h(s);
}
return s;
}
Welche mathematischen Modelle werden im Compilerbau benutzt?